How to implement K-Nearest Neighbors Algorithm in Python and Scikit-Learn
The K-nearest neighbors (KNN) algorithm is a type of supervised machine learning algorithms. KNN is extremely easy to implement in its most basic form, and yet performs quite complex classification tasks. It is a lazy learning algorithm since it doesn’t have a specialized training phase. Rather, it uses all of the data for training while classifying a new data point or instance. KNN is a non-parametric learning algorithm, which means that it doesn’t assume anything about the underlying data. This is an extremely useful feature since most of the real world data doesn’t really follow any theoretical assumption e.g. linear-separability, uniform distribution, etc.
In this article, we will see how KNN can be implemented with Python’s Scikit-Learn library. But before that let’s first explore the theory behind KNN and see what are some of the pros and cons of the algorithm.
Theory
The intuition behind the KNN algorithm is one of the simplest of all the supervised machine learning algorithms. It simply calculates the distance of a new data point to all other training data points. The distance can be of any type e.g Euclidean or Manhattan etc. It then selects the K-nearest data points, where K can be any integer. Finally it assigns the data point to the class to which the majority of the K data points belong.
Let’s see this algorithm in action with the help of a simple example. Suppose you have a dataset with two variables, which when plotted, looks like the one in the following figure.
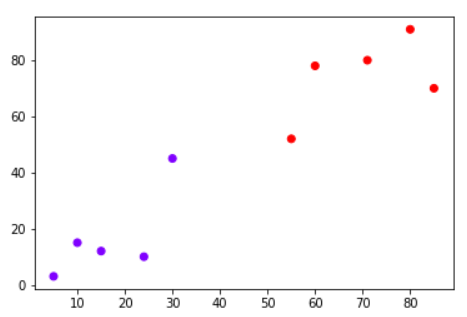
Your task is to classify a new data point with ‘X’ into “Blue” class or “Red” class. The coordinate values of the data point are x=45 and y=50. Suppose the value of K is 3. The KNN algorithm starts by calculating the distance of point X from all the points. It then finds the 3 nearest points with least distance to point X. This is shown in the figure below. The three nearest points have been encircled.
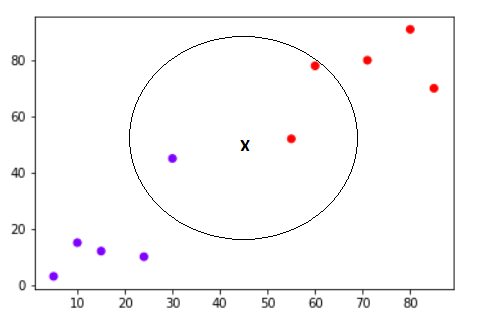
The final step of the KNN algorithm is to assign new point to the class to which majority of the three nearest points belong. From the figure above we can see that the two of the three nearest points belong to the class “Red” while one belongs to the class “Blue”. Therefore the new data point will be classified as “Red”.
Pros and Cons of KNN
In this section we’ll present some of the pros and cons of using the KNN algorithm.
Pros
- It is extremely easy to implement
- As said earlier, it is lazy learning algorithm and therefore requires no training prior to making real time predictions. This makes the KNN algorithm much faster than other algorithms that require training e.g SVM, linear regression, etc.
- Since the algorithm requires no training before making predictions, new data can be added seamlessly.
- There are only two parameters required to implement KNN i.e. the value of K and the distance function (e.g. Euclidean or Manhattan etc.)
Cons
- The KNN algorithm doesn’t work well with high dimensional data because with large number of dimensions, it becomes difficult for the algorithm to calculate distance in each dimension.
- The KNN algorithm has a high prediction cost for large datasets. This is because in large datasets the cost of calculating distance between new point and each existing point becomes higher.
- Finally, the KNN algorithm doesn’t work well with categorical features since it is difficult to find the distance between dimensions with categorical features.
Implementing KNN Algorithm with Scikit-Learn
In this section, we will see how Python’s Scikit-Learn library can be used to implement the KNN algorithm in less than 20 lines of code. The download and installation instructions for Scikit learn library are available at here.
Note: The code provided in this tutorial has been executed and tested with Python Jupyter notebook.
The Dataset
We are going to use the famous iris data set for our KNN example. The dataset consists of four attributes: sepal-width, sepal-length, petal-width and petal-length. These are the attributes of specific types of iris plant. The task is to predict the class to which these plants belong. There are three classes in the dataset: Iris-setosa, Iris-versicolor and Iris-virginica. Further details of the dataset are available here.
Importing Libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
Importing the Dataset
To import the dataset and load it into our pandas dataframe, execute the following code:
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
/* Assign colum names to the dataset */
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class']
/* Read dataset to pandas dataframe */
dataset = pd.read_csv(url, names=names)
To see what the dataset actually looks like, execute the following command:
dataset.head()
Executing the above script will display the first five rows of our dataset as shown below:
| sepal-length | sepal-width | petal-length | petal-width | Class | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
Preprocessing
The next step is to split our dataset into its attributes and labels. To do so, use the following code:
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 4].values
The X variable contains the first four columns of the dataset (i.e. attributes) while y contains the labels.
Train Test Split
To avoid over-fitting, we will divide our dataset into training and test splits, which gives us a better idea as to how our algorithm performed during the testing phase. This way our algorithm is tested on un-seen data, as it would be in a production application.
To create training and test splits, execute the following script:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)
The above script splits the dataset into 80% train data and 20% test data. This means that out of total 150 records, the training set will contain 120 records and the test set contains 30 of those records.
Feature Scaling
Before making any actual predictions, it is always a good practice to scale the features so that all of them can be uniformly evaluated. Wikipedia explains the reasoning pretty well:
Since the range of values of raw data varies widely, in some machine learning algorithms, objective functions will not work properly without normalization. For example, the majority of classifiers calculate the distance between two points by the Euclidean distance. If one of the features has a broad range of values, the distance will be governed by this particular feature. Therefore, the range of all features should be normalized so that each feature contributes approximately proportionately to the final distance.
The gradient descent algorithm (which is used in neural network training and other machine learning algorithms) also converges faster with normalized features.
The following script performs feature scaling:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
Training and Predictions
It is extremely straight forward to train the KNN algorithm and make predictions with it, especially when using Scikit-Learn.
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors=5)
classifier.fit(X_train, y_train)
The first step is to import the KNeighborsClassifier class from the sklearn.neighbors library. In the second line, this class is initialized with one parameter, i.e. n_neigbours. This is basically the value for the K. There is no ideal value for K and it is selected after testing and evaluation, however to start out, 5 seems to be the most commonly used value for KNN algorithm.
The final step is to make predictions on our test data. To do so, execute the following script:
y_pred = classifier.predict(X_test)
Evaluating the Algorithm
For evaluating an algorithm, confusion matrix, precision, recall and f1 score are the most commonly used metrics. The confusion_matrix and classification_report methods of the sklearn.metrics can be used to calculate these metrics. Take a look at the following script:
from sklearn.metrics import classification_report, confusion_matrix
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
The output of the above script looks like this:
[[11 0 0]
0 13 0]
0 1 6]]
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 11
Iris-versicolor 1.00 1.00 1.00 13
Iris-virginica 1.00 1.00 1.00 6
avg / total 1.00 1.00 1.00 30The results show that our KNN algorithm was able to classify all the 30 records in the test set with 100% accuracy, which is excellent. Although the algorithm performed very well with this dataset, don’t expect the same results with all applications. As noted earlier, KNN doesn’t always perform as well with high-dimensionality or categorical features.
Comparing Error Rate with the K Value
In the training and prediction section we said that there is no way to know beforehand which value of K that yields the best results in the first go. We randomly chose 5 as the K value and it just happen to result in 100% accuracy.
One way to help you find the best value of K is to plot the graph of K value and the corresponding error rate for the dataset.
In this section, we will plot the mean error for the predicted values of test set for all the K values between 1 and 40.
To do so, let’s first calculate the mean of error for all the predicted values where K ranges from 1 and 40. Execute the following script:
error = []
/* Calculating error for K values between 1 and 40 */
for i in range(1, 40):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(X_train, y_train)
pred_i = knn.predict(X_test)
error.append(np.mean(pred_i != y_test))
The above script executes a loop from 1 to 40. In each iteration the mean error for predicted values of test set is calculated and the result is appended to the error list.
The next step is to plot the error values against K values. Execute the following script to create the plot:
plt.figure(figsize=(12, 6))
plt.plot(range(1, 40), error, color='red', linestyle='dashed', marker='o',
markerfacecolor='blue', markersize=10)
plt.title('Error Rate K Value')
plt.xlabel('K Value')
plt.ylabel('Mean Error')
The output graph looks like this:
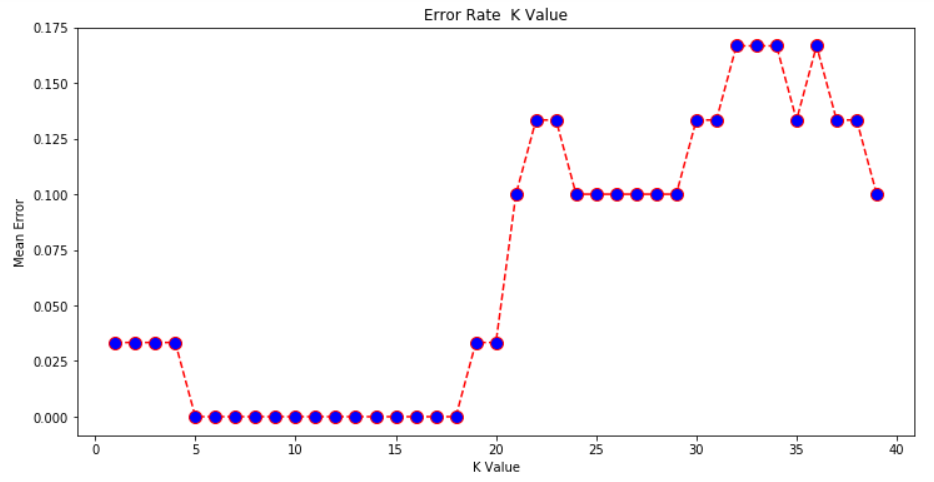
From the output we can see that the mean error is zero when the value of the K is between 5 and 18. I would advise you to play around with the value of K to see how it impacts the accuracy of the predictions.
Conclusion
KNN is a simple yet powerful classification algorithm. It requires no training for making predictions, which is typically one of the most difficult parts of a machine learning algorithm. The KNN algorithm have been widely used to find document similarity and pattern recognition. It has also been employed for developing recommender systems and for dimensionality reduction and pre-processing steps for computer vision, particularly face recognition tasks.
Python Example for Beginners

Two Machine Learning Fields
There are two sides to machine learning:
- Practical Machine Learning:This is about querying databases, cleaning data, writing scripts to transform data and gluing algorithm and libraries together and writing custom code to squeeze reliable answers from data to satisfy difficult and ill defined questions. It’s the mess of reality.
- Theoretical Machine Learning: This is about math and abstraction and idealized scenarios and limits and beauty and informing what is possible. It is a whole lot neater and cleaner and removed from the mess of reality.
Data Science Resources: Data Science Recipes and Applied Machine Learning Recipes
Introduction to Applied Machine Learning & Data Science for Beginners, Business Analysts, Students, Researchers and Freelancers with Python & R Codes @ Western Australian Center for Applied Machine Learning & Data Science (WACAMLDS) !!!
Latest end-to-end Learn by Coding Recipes in Project-Based Learning:
Applied Statistics with R for Beginners and Business Professionals
Data Science and Machine Learning Projects in Python: Tabular Data Analytics
Data Science and Machine Learning Projects in R: Tabular Data Analytics
Python Machine Learning & Data Science Recipes: Learn by Coding
R Machine Learning & Data Science Recipes: Learn by Coding
Comparing Different Machine Learning Algorithms in Python for Classification (FREE)
Disclaimer: The information and code presented within this recipe/tutorial is only for educational and coaching purposes for beginners and developers. Anyone can practice and apply the recipe/tutorial presented here, but the reader is taking full responsibility for his/her actions. The author (content curator) of this recipe (code / program) has made every effort to ensure the accuracy of the information was correct at time of publication. The author (content curator) does not assume and hereby disclaims any liability to any party for any loss, damage, or disruption caused by errors or omissions, whether such errors or omissions result from accident, negligence, or any other cause. The information presented here could also be found in public knowledge domains.