Understanding Overfitting in Machine Learning: A Comprehensive Guide
In the realm of machine learning, one of the most common pitfalls that both beginners and experienced practitioners can fall into is overfitting. Overfitting refers to a model that performs well on the training data but poorly on unseen data, indicating that the model has not generalized well from the training data. This comprehensive guide aims to provide an in-depth exploration of overfitting, offering practical examples and prompts to help you understand and avoid this common issue.
The Overfitting Problem
When you first start out with machine learning, you might think that the more data you use to train your model, the better it will perform. It seems reasonable to assume that evaluating the model and reporting results on the same dataset will tell you how good the model is. However, this is a misconception.
The best model for a given dataset is the dataset itself. If you take a given data instance and ask for its classification, you can look that instance up in the dataset and report the correct result every time. This is the problem you are solving when you train and test a model on the same dataset. You are asking the model to make predictions on data that it has “seen” before. Data that was used to create the model. The best model for this problem is the look-up model described above.
Descriptive vs Predictive Models
There are some circumstances where you do want to train a model and evaluate it with the same dataset. You may want to simplify the explanation of a predictive variable from data. For example, you may want a set of simple rules or a decision tree that best describes the observations you have collected. In this case, you are building a descriptive model.
The important limitation of a descriptive model is that it is limited to describing the data on which it was trained. You have no idea how accurate a predictive the model it is.
On the other hand, a predictive model is attempting a much more difficult problem, approximating the true discrimination function from a sample of data. We want to use algorithms that do not pick out and model all of the noise in our sample. We do want to choose algorithms that generalize beyond the observed data. It makes sense that we could only evaluate the ability of the model to generalize from a data sample on data that it had not seen before during training.
Overfitting and Its Consequences
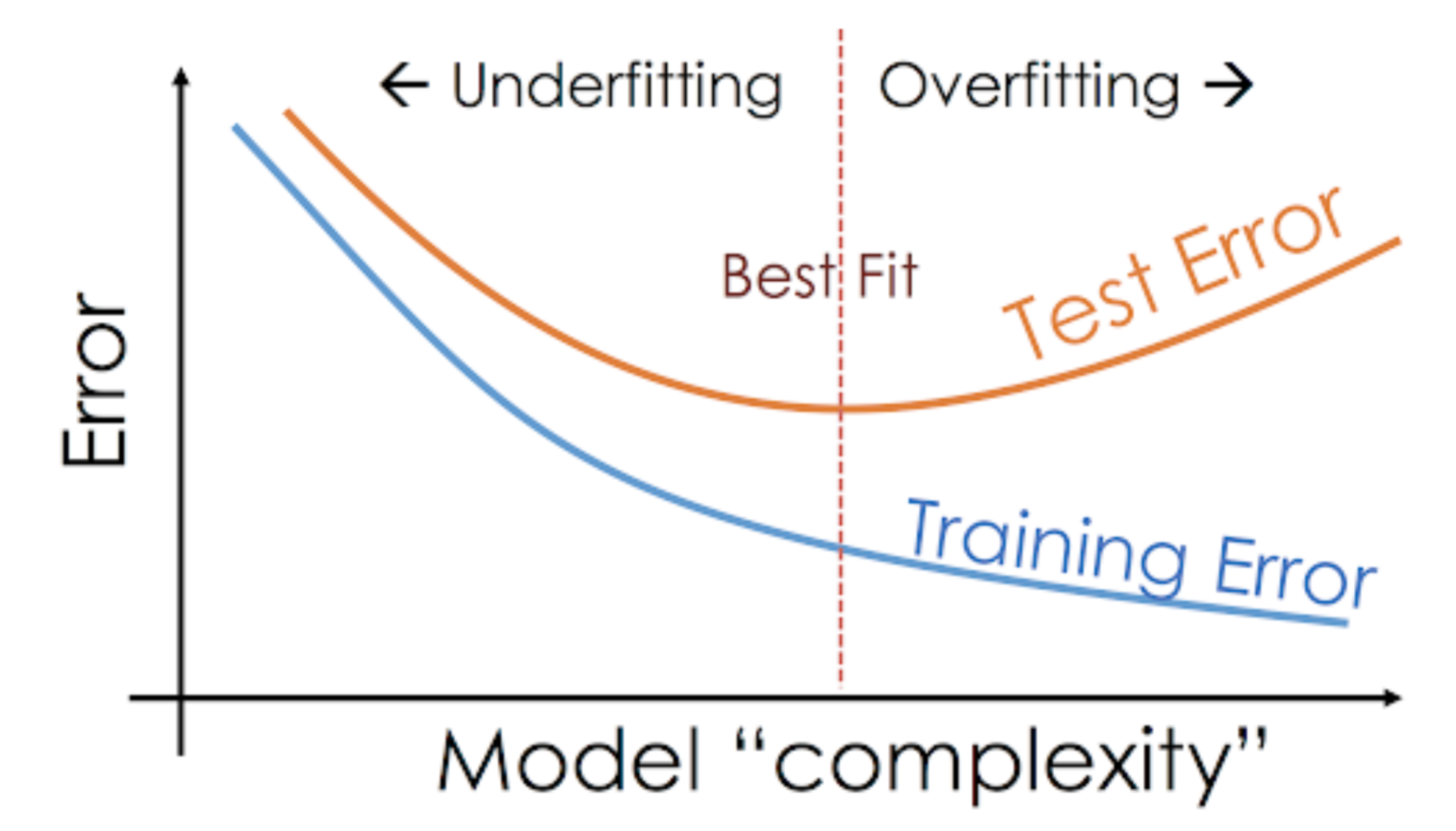
The flaw with evaluating a predictive model on training data is that it does not inform you on how well the model has generalized to new unseen data. A model that is selected for its accuracy on the training dataset rather than its accuracy on an unseen test dataset is very likely to have lower accuracy on an unseen test dataset. The reason is that the model is not as generalized. It has specialized to the structure in the training dataset. This is called overfitting, and it’s more insidious than you think.
For example, you may want to stop training your model once the accuracy stops improving. In this situation, there will be a point where the accuracy on the training set continues to improve but the accuracy on unseen data starts to degrade.
Tackling Overfitting
You must test your model on unseen data to counter overfitting. A split of data 66%/34% for training to test datasets is a good start. Using cross-validation is better, and using multiple runs of cross-validation is better again. You want to spend the time and get the best estimate of the model’s accuracy on unseen data.
You can increase the accuracy of your model by decreasing its complexity. In the case of decision trees, for example, you can prune the tree (delete leaves) after training. This will decrease the amount of specialization in the specific training dataset and increase generalization on unseen data. If you are using regression, for example, you can use regularization to constrain the complexity (magnitude of the coefficients) during the training process.
Relevant Prompts for Understanding Overfitting
To help you get started with understanding overfitting, here are some prompts that you can use:
1. “What is overfitting in machine learning and why is it a problem?”
2. “Can you explain the difference between a descriptive model and a predictive model?”
3. “Why is it a bad idea to train and test a model on the same dataset?”
4. “What are some strategies to prevent overfitting in machine learning models?”
5. “How does cross-validation help in preventing overfitting?”
6. “What is the role of regularization in preventing overfitting in regression models?”
7. “Can you explain how decision tree pruning can help prevent overfitting?”
8. “Why is it important to split the dataset into training and test sets?”
9. “How does overfitting affect the performance of a machine learning model on unseen data?”
10. “What are some signs that a machine learning model might be overfitting?”
In conclusion, understanding overfitting is crucial in machine learning. It helps you build models that not only perform well on your training data but also generalize well to unseen data. By understanding the concept of overfitting and how to prevent it, you can build more robust and accurate machine learning models.
Find more … …
Unlocking the Power of Validation Sets in Machine Learning: A Comprehensive Exploration
Machine Learning for Beginners – A Guide to monitor overfitting of a XGBoost model in Python
Applied Data Science Coding in Python: How to get Classification Accuracy