Introduction: The Challenge of Continuous Variables in Predictive Modeling
Continuous variables, those numerical variables that can take on any value within a certain range, are a common feature in many datasets used for predictive modeling. While these variables often hold valuable predictive information, they can also present challenges due to their continuous nature and wide range of possible values. This comprehensive guide will delve into various strategies for effectively dealing with continuous variables in predictive modeling, discussing their advantages, potential pitfalls, and best practices.
1. Understanding Continuous Variables
Continuous variables can take any value within a given range and can be divided into an infinite number of possible values. Examples include height, weight, temperature, or time. Their continuous nature often requires specialized handling in predictive modeling to ensure the algorithms can process the data effectively and derive useful insights.
2. Techniques for Dealing with Continuous Variables
There are several techniques available for dealing with continuous variables, each with its unique strengths and drawbacks.
2.1 Binning
Binning is a technique that involves dividing the range of a continuous variable into distinct categories, or “bins”, effectively converting the continuous variable into a categorical one. This can simplify the modeling process and help manage outliers, but it also risks losing information due to the reduction in data granularity.
2.2 Scaling and Normalization
Scaling involves adjusting the range of the continuous variable, while normalization adjusts the distribution of the variable. These techniques can help ensure that all variables are on a similar scale, which can improve the performance of certain machine learning algorithms. However, these methods may not be suitable for all types of data and algorithms.
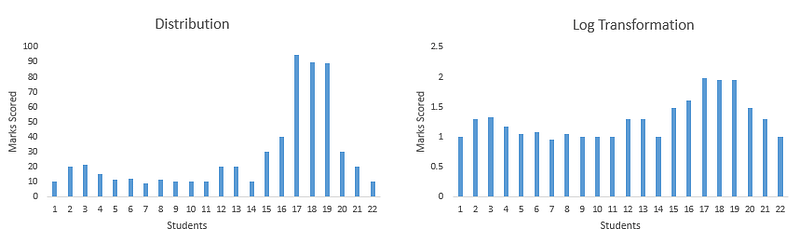
2.3 Logarithmic Transformation
Logarithmic transformation can help manage skewed distributions and reduce the impact of outliers. This transformation adjusts the scale of the data, making it easier for some algorithms to interpret. However, it’s essential to remember that not all data are suitable for log transformation.
2.4 Polynomial Features
Creating polynomial features involves generating new features by raising existing continuous variables to a power. This can help capture non-linear relationships between the variable and the target, but it can also increase the complexity of the model and risk overfitting.
2.5 Interaction Features
Interaction features are created by combining two or more variables. This can help capture relationships between variables that the model might otherwise miss. However, like polynomial features, interaction features can also increase the complexity of the model.
2.6 Feature Discretization
Feature discretization is similar to binning, but rather than creating arbitrary bins, it involves creating bins that reflect the distribution of the data. This can help capture important patterns in the data, but it may also introduce complexity into the model.
2.7 Handling Outliers
Outliers, or extreme values, can have a significant impact on the performance of predictive models. Techniques for handling outliers include trimming (removing outliers), winsorizing (replacing outliers with the nearest non-outlier values), or using robust models that are less sensitive to outliers.
2.8 Feature Selection
Feature selection involves choosing the most relevant features for the predictive model. This can help reduce the complexity of the model and improve interpretability. Techniques for feature selection include filter methods, wrapper methods, and embedded methods.
3. Best Practices for Handling Continuous Variables
When dealing with continuous variables in predictive modeling, consider the following best practices:
3.1 Understand Your Data
Before applying any transformations or techniques, it’s essential to understand the nature of your continuous variables. Consider their distributions, relationships with the target variable, and presence of outliers.
3.2 Choose Appropriate Techniques
Different techniques are suitable for different types of data and problems. For instance, if your data contains significant outliers, winsorizing or robust modeling may be appropriate.
3.3 Preserve Information
When transforming or binning continuous variables, be careful not to lose essential information. While these transformations can simplify the modeling process, they also reduce the granularity of the data.
3.4 Avoid Overfitting
Techniques like polynomial and interaction features can increase the complexity of your model, which can lead to overfitting. Always validate your model on unseen data to ensure it generalizes well.
3.5 Experiment with Different Techniques
Don’t be afraid to experiment with different techniques and combinations thereof. The effectiveness of each technique can vary depending on the specific dataset and problem.
4. Advanced Techniques for Handling Continuous Variables
Advanced machine learning techniques can offer additional ways to handle continuous variables effectively:
4.1 Deep Learning
Deep learning algorithms, such as neural networks, can handle continuous variables effectively due to their ability to capture complex, non-linear relationships.
4.2 Ensemble Methods
Ensemble methods, like random forests and gradient boosting, can also handle continuous variables well. These methods work by combining multiple weak learners to form a strong learner, which can capture complex patterns in the data.
Summary
Dealing with continuous variables effectively is crucial in predictive modeling, as these variables often hold significant predictive power but can also present challenges due to their continuous nature and wide range of possible values. This comprehensive guide has explored various techniques for handling continuous variables, their pros and cons, and best practices for their use. By understanding and applying these techniques, data scientists and analysts can harness the full potential of continuous variables in their predictive modeling tasks, leading to more accurate and robust models.
Find more … …
Statistics for Beginners in Excel – Dealing with Missing Data
Statistics for Beginners – Continuous Probability Distributions