Introduction to Text Data Cleaning in Python
Text data cleaning, also known as text preprocessing, is an essential step in natural language processing (NLP) and machine learning, as it prepares raw text data for analysis, modeling, and visualization. This comprehensive guide provides an in-depth look at text data cleaning in Python, covering various techniques, tools, and best practices to help you effectively preprocess text data for NLP and machine learning applications.
1. The Importance of Text Data Cleaning
Text data cleaning is crucial for several reasons:
a. Noise Reduction: Raw text data often contains noise, such as irrelevant characters, misspellings, and inconsistent formatting. Cleaning text data helps remove this noise, improving the quality and reliability of your analysis.
b. Standardization: Text data cleaning ensures that the data is in a consistent and standardized format, which is critical for effective analysis and modeling.
c. Feature Extraction: Cleaning text data enables the extraction of meaningful features and patterns from the text, enhancing the performance of NLP and machine learning algorithms.
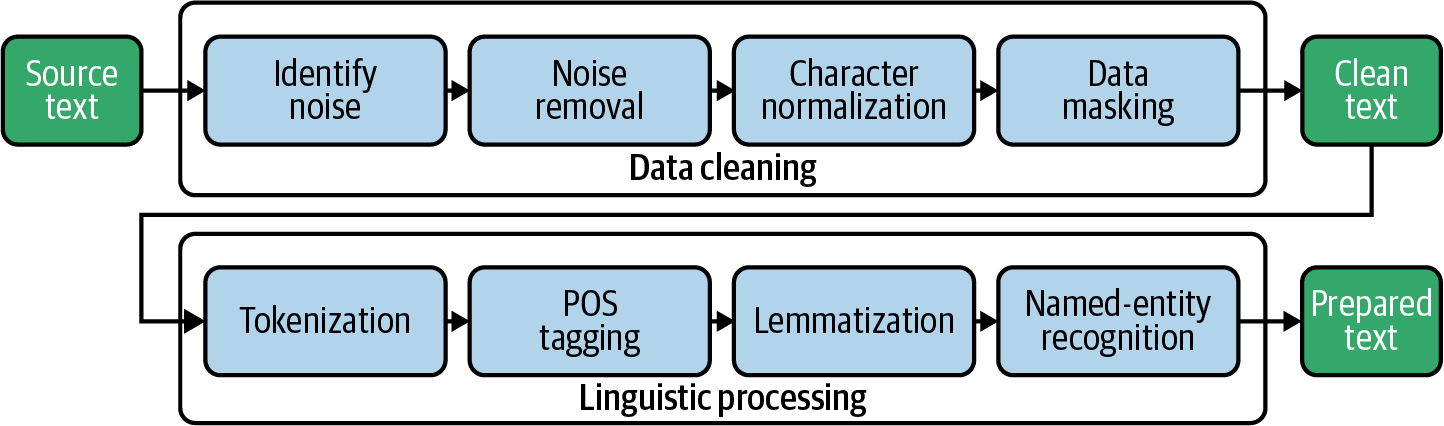
2. Common Text Data Cleaning Techniques
Various techniques can be employed to clean text data in Python, including:
a. Lowercasing: Convert all text to lowercase to ensure consistency and reduce the dimensionality of the data.
b. Tokenization: Break text into individual words or tokens for further analysis and processing.
c. Stopword Removal: Remove common words, such as “the,” “and,” and “in,” that do not carry significant meaning and may introduce noise into the analysis.
d. Punctuation and Special Character Removal: Eliminate punctuation marks and special characters that may not be relevant to the analysis.
e. Lemmatization and Stemming: Reduce words to their base or root form to enable accurate comparison and analysis.
f. Spell Checking and Correction: Identify and correct spelling errors and typos in the text data.
3. Python Libraries for Text Data Cleaning
Several Python libraries are available for text data cleaning, including:
a. NLTK (Natural Language Toolkit): A popular library for NLP and text analysis that provides various tools for text preprocessing, including tokenization, stopword removal, and stemming.
b. spaCy: A high-performance NLP library that offers advanced text preprocessing features, such as tokenization, part-of-speech tagging, and named entity recognition.
c. TextBlob: A simple NLP library that provides tools for text preprocessing, sentiment analysis, and language detection.
d. re (Regular Expressions): A built-in Python library for working with regular expressions, which can be used to remove or manipulate specific patterns in the text data.
4. Text Data Cleaning Workflow in Python
To clean text data in Python, follow these steps:
a. Load Data: Import the raw text data into Python using appropriate libraries, such as pandas or open().
b. Inspect Data: Examine the text data to identify potential issues, such as inconsistent formatting, spelling errors, and irrelevant content.
c. Apply Cleaning Techniques: Apply the necessary text data cleaning techniques, such as lowercasing, tokenization, and stopword removal, using Python libraries like NLTK, spaCy, or TextBlob.
d. Validate Results: Check the cleaned text data to ensure that the cleaning techniques have been applied correctly and that the data is now in a consistent and standardized format.
5. Best Practices for Text Data Cleaning in Python
Follow these best practices to ensure effective and efficient text data cleaning in Python:
a. Understand the Data and the Problem: Before cleaning the text data, familiarize yourself with the data and the problem you are trying to solve. This will help you determine which cleaning techniques are most appropriate for your specific use case and objectives.
b. Use Appropriate Libraries and Tools: Select the most suitable Python libraries and tools for your text data cleaning needs, considering factors such as performance, ease of use, and compatibility with your existing workflow.
c. Customize Cleaning Techniques: Customize and fine-tune the text data cleaning techniques to address the specific requirements and challenges of your data. For example, you may need to create custom stopword lists, regular expressions, or tokenization rules to handle domain-specific terminology, abbreviations, or slang.
d. Automate and Streamline the Process: Develop reusable functions, scripts, or pipelines to automate and streamline the text data cleaning process, ensuring consistency and efficiency in your workflow.
e. Validate and Iterate: Regularly validate the results of your text data cleaning process to ensure that it is effectively addressing the issues in your data. Be prepared to iterate and adjust your cleaning techniques as necessary to optimize performance and accuracy.
f. Document Your Workflow: Maintain clear and thorough documentation of your text data cleaning workflow, including the techniques, tools, and assumptions used. This will facilitate collaboration, reproducibility, and future improvements to your process.
Summary
Text data cleaning is a critical aspect of NLP and machine learning, ensuring that raw text data is transformed into a consistent, standardized, and meaningful format for analysis, modeling, and visualization. By mastering the various techniques, tools, and best practices for text data cleaning in Python, you can enhance the quality, reliability, and performance of your NLP and machine learning applications. As the demand for data-driven insights and decision-making continues to grow across diverse sectors and disciplines, the ability to effectively preprocess and clean text data will become an increasingly valuable skill for researchers, analysts, and professionals alike.