


Introduction: Unleashing the Power of Ensemble Modeling in Machine Learning
Ensemble modeling is a powerful technique in machine learning that involves combining multiple models to improve overall performance and achieve more accurate predictions. By leveraging the strengths of individual models, ensemble methods can mitigate weaknesses and reduce errors, making them an essential tool for data scientists and machine learning practitioners. In this comprehensive guide, we will explore the core concepts of ensemble modeling, discuss various selection techniques for building effective ensembles, and provide best practices for implementing and optimizing ensemble models in real-world scenarios.
Core Concepts of Ensemble Modeling
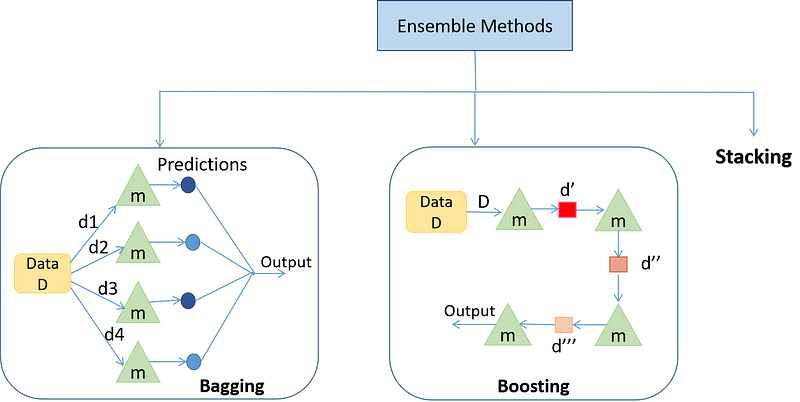
Ensemble modeling is based on the idea that a group of weak learners can collectively form a strong learner when their predictions are combined. The primary goal of ensemble modeling is to reduce the bias and variance of individual models, leading to more robust and accurate predictions. There are two main types of ensemble methods:
1. Bagging (Bootstrap Aggregating): Bagging involves creating multiple versions of the original dataset through random sampling with replacement, training a base model on each version, and aggregating the predictions. This technique reduces variance and overfitting while maintaining model stability.
2. Boosting: Boosting iteratively trains a series of base models, with each model focusing on correcting the errors made by the previous model. The predictions of these models are then combined using a weighted majority vote, resulting in a more accurate final model. Boosting reduces bias and helps create strong learners from weak ones.
Selection Techniques for Ensemble Modeling
Choosing the right base models and ensemble techniques is critical for building a successful ensemble model. Some of the popular selection techniques for ensemble modeling include:
1. Model Averaging: This technique involves training multiple models with different architectures, hyperparameters, or training datasets, and averaging their predictions to create a final ensemble prediction. Model averaging is a simple yet effective method for reducing overfitting and improving model performance.
2. Stacking: Stacking involves training multiple base models and using their predictions as input for a meta-model (also known as a second-level model). The meta-model then combines these predictions to create a final ensemble prediction. Stacking allows for the exploitation of complementary strengths and weaknesses among different base models.
3. Voting: Voting combines the predictions of multiple models through a majority vote, with each model receiving equal weight. Voting can be hard (based on class labels) or soft (based on class probabilities). Soft voting is generally preferred, as it accounts for the confidence levels of individual model predictions.
4. Weighted Combination: In weighted combination, base models are assigned weights based on their performance or some other metric, and the weighted predictions are combined to form the ensemble prediction. This approach ensures that models with higher performance contribute more to the final prediction.
Best Practices for Implementing and Optimizing Ensemble Models
1. Diversity of Base Models: Using a diverse set of base models is essential for creating a strong ensemble. Diversity can be achieved by using different algorithms, varying hyperparameters, or training on different subsets of the dataset.
2. Cross-validation: Cross-validation is crucial for estimating model performance and selecting the best ensemble technique. Perform k-fold cross-validation to evaluate the performance of individual base models and the ensemble as a whole.
3. Model Interpretability: Ensemble models can be more complex and harder to interpret than single models. Consider using techniques like feature importance, partial dependence plots, and local interpretable model-agnostic explanations (LIME) to enhance model interpretability.
4. Regularization: Regularization techniques like Lasso or Ridge can help prevent overfitting in ensemble models, especially when dealing with high-dimensional datasets.
5. Hyperparameter Tuning: Optimizing hyperparameters of base models and ensemble techniques can significantly improve the performance of the final ensemble model. Use techniques like grid search, random search, or Bayesian optimization to find the optimal hyperparameter settings.
6. Performance Metrics: Choose appropriate performance metrics based on the problem at hand, such as accuracy, precision, recall, F1 score, or area under the receiver operating characteristic (ROC) curve. These metrics will help you assess the performance of your ensemble model and identify areas for improvement.
7. Scalability and Computational Efficiency: Ensemble models can be computationally expensive, especially when dealing with large datasets and complex base models. Consider using parallelization, distributed computing, or other efficiency-enhancing techniques to speed up the training and prediction process.
8. Model Selection and Pruning: Selecting the right combination of base models is crucial for building a successful ensemble. Experiment with different base models, ensemble techniques, and selection strategies to find the most effective configuration. Pruning techniques, such as forward or backward selection, can help you identify and remove weak or redundant models from the ensemble.
9. Ensemble Model Evaluation: Regularly evaluate the performance of your ensemble model to ensure it continues to meet your desired level of accuracy and robustness. Track changes in performance metrics over time and update your ensemble model as needed to maintain optimal performance.
10. Continuous Learning and Model Updating: Ensemble models, like any machine learning model, can become outdated as new data becomes available or the underlying patterns in the data change. Implement continuous learning and model updating strategies to keep your ensemble model up-to-date and relevant.
Conclusion
Ensemble modeling is a powerful technique for improving the accuracy and robustness of machine learning models by combining the strengths of multiple base models. By understanding the core concepts of ensemble modeling, implementing various selection techniques, and following best practices for optimization, data scientists and machine learning practitioners can build highly effective ensemble models to tackle even the most challenging real-world problems. As with any machine learning technique, continuous learning and model updating are crucial for maintaining the effectiveness and relevance of ensemble models in a rapidly changing data landscape.
Find more … …
Applied Machine Learning with Ensembles: Random Forest Ensembles