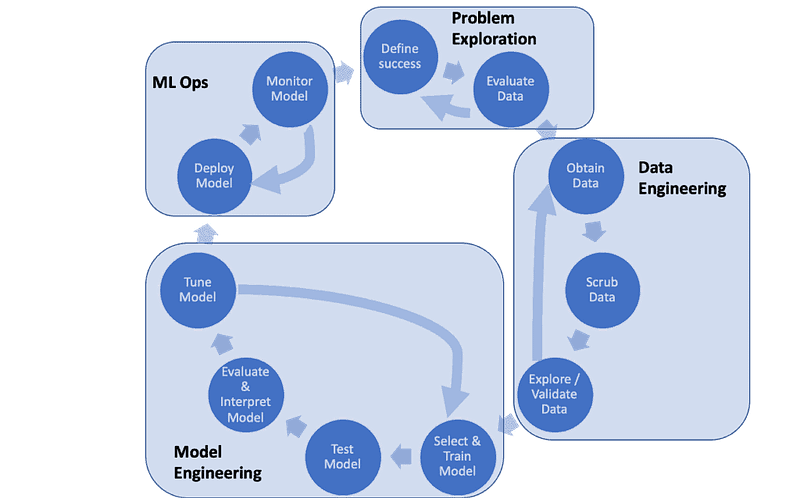
Introduction
Data preparation is arguably one of the most critical steps in a machine learning project. It involves transforming raw data into a format that is suitable for machine learning algorithms. While algorithms and models may get a lot of attention, quality data and its preparation are the foundation of any successful machine learning project. This comprehensive guide will provide you with the necessary steps and techniques to effectively prepare your data for machine learning.
Understanding Data Preparation
Before diving into the methods of data preparation, it’s important to understand why this step is so vital. Machine learning algorithms learn from data. The quality of the data and how it’s presented can significantly impact the learning process.
For example, missing or inconsistent data can lead to unreliable and poor-quality outcomes. Similarly, if data is not correctly normalized or scaled, some algorithms may give undue importance to certain features, leading to biases in the predictions.
Data Collection
Data preparation begins with data collection. This involves gathering data relevant to the problem you’re trying to solve. The data could come from various sources such as databases, files, data streams, APIs, web scraping, or even be generated synthetically.
Keep in mind that the data should be representative of the problem space for the machine learning model to be effective. It’s also important to gather as much data as possible. More data usually means more information for your model to learn from, leading to better predictions.
Data Cleaning
Once the data is collected, the next step is data cleaning. This step aims to address and rectify the problems that are common in real-world data, including:
Missing Values: Data can have missing values due to various reasons, such as errors in data collection or certain measurements not being applicable. Depending on the situation, you might fill in missing values with a certain value (like the mean or median of the data), use a model to predict the missing values, or drop the rows or columns with missing values.
Outliers: Outliers are data points that are significantly different from the rest of the data. They can be due to variability in the data or errors in data collection. Outliers can often skew the results of your machine learning model. Identifying and handling outliers is a crucial step in data cleaning.
Duplicate Values: Sometimes, data can have duplicate entries. These duplicates can bias your machine learning model, so it’s important to identify and remove them.
Data Transformation
Data transformation involves converting the data into a format that is more suitable for machine learning. This can involve several steps:
Feature Scaling: Many machine learning algorithms perform better when numerical input variables are scaled to a standard range. This can involve normalization (scaling the feature to a range of 0–1) or standardization (scaling the feature to have a mean of 0 and a standard deviation of 1).
Encoding Categorical Variables: Machine learning algorithms expect numerical input. So, if your data contains categorical variables (like ‘color’ or ‘city’), you’ll need to encode these variables into numbers. This can be done through various techniques like one-hot encoding or label encoding.
Feature Engineering: This involves creating new features from existing ones. Good features can often make the difference between a mediocre model and a great one. Feature engineering might involve techniques like binning, polynomial features, or interaction features.
Data Splitting
Once the data is cleaned and transformed, the final step in data preparation is to split the data. Typically, data is split into a training set, a validation set, and a test set. The training set is used to train the machine learning model, the validation set is used to tune hyperparameters and make decisions on the model structure, and the test set is used to evaluate the final model’s performance. This process helps to ensure that the model can generalize well to new, unseen data, which is crucial for its effectiveness when deployed in real-world scenarios.
Splitting the data is not always straightforward. For example, in time-series data, it’s important to maintain temporal order, so a simple random split might not be appropriate. Similarly, if the data is imbalanced (i.e., one class has many more examples than another), you might need to use techniques such as stratified sampling to ensure that the train, validation, and test sets all have the same proportion of classes.
Automating Data Preparation
Given the importance of data preparation, it’s not surprising that a lot of work is going into automating this process. Automated data preparation tools can handle tasks such as handling missing data, feature scaling, and encoding categorical variables. However, these tools should be used with caution. While they can save time, they also remove control from the data scientist, who might have specific domain knowledge that could guide the data preparation process.
The Role of Domain Knowledge
While this guide provides general steps for data preparation, the specifics of how each step is carried out can depend heavily on the problem domain. Domain knowledge can guide how you clean your data, engineer features, and split your data. It can also help you understand and interpret the results of your machine learning model. Therefore, while technical skills are essential for data preparation, don’t underestimate the importance of domain knowledge.
Summary
Data preparation may not be the most glamorous part of a machine learning project, but it’s undoubtedly one of the most crucial. It involves several steps, from data collection and cleaning to transformation and splitting, each of which can significantly impact the performance of your machine learning model.
While the process can be time-consuming and sometimes tedious, the payoff is worth it. Good data preparation can lead to more accurate models, faster training times, and ultimately, more successful machine learning projects. And with the advent of automated data preparation tools, some of these tasks can be made more manageable, freeing you up to focus on other parts of your project.
So don’t skimp on data preparation. Take the time to understand your data, clean it, transform it, and split it correctly. Your machine learning model will thank you for it!
Find more … …
Data Science vs. Data Analytics vs. Machine Learning – What are the difference among them?