

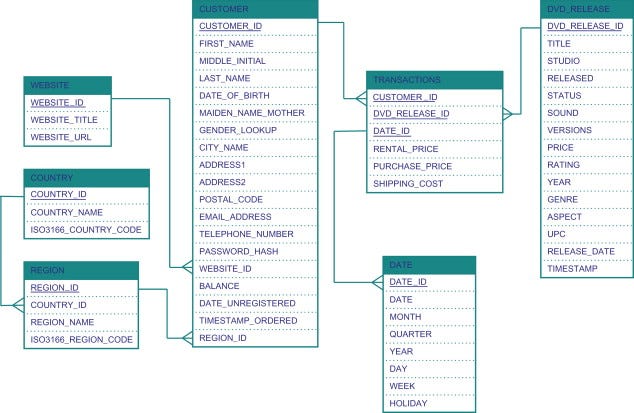

Introduction to Snowflake Schema in Data Warehouse Modeling
The snowflake schema is a popular data warehouse modeling technique that offers a balance between query performance and data integrity. As a variation of the star schema, the snowflake schema is characterized by its normalized dimension tables, which can result in a more complex structure. This comprehensive guide will explore the concepts, design principles, and advantages of the snowflake schema in data warehouse modeling, providing a deep understanding of how it can be effectively applied in various industries and use cases.
Snowflake Schema: Core Concepts and Components
The snowflake schema is a type of dimensional modeling technique that organizes data into a central fact table and one or more surrounding dimension tables. However, unlike the star schema, the dimension tables in a snowflake schema are normalized, which means they are broken down into multiple related tables to eliminate redundancy and improve data integrity. To better understand the snowflake schema, it is essential to familiarize yourself with its key components:
Fact Table: The fact table is the central table in a snowflake schema that stores the numerical data, such as sales, revenue, or profit. Fact tables contain fact records, which represent individual transactions or events, along with foreign keys that reference the associated dimension tables.
Dimension Table: Dimension tables are connected to the fact table via primary and foreign key relationships and store the descriptive information, such as customer details, product information, or date attributes. In a snowflake schema, the dimension tables are normalized, resulting in a more complex structure with multiple levels of related dimension tables.
Normalization: Normalization is the process of organizing data in a database to reduce redundancy and improve data integrity. In a snowflake schema, dimension tables are normalized, which leads to a more complex structure compared to the denormalized dimension tables in a star schema.
Design Principles for Snowflake Schema in Data Warehouse Modeling
When designing a snowflake schema for a data warehouse, consider the following key principles:
Normalization: Snowflake schema design involves normalizing the dimension tables to eliminate redundancy and improve data integrity. While normalization can lead to a more complex structure, it can also help maintain consistent and accurate data throughout the data warehouse.
Surrogate Keys: Use surrogate keys, which are system-generated, unique identifiers, for the primary keys in dimension tables. Surrogate keys can improve query performance and maintain data integrity, as they are not affected by changes in the natural keys (i.e., keys derived from the actual data).
Data Granularity: Determine the appropriate level of granularity for your fact table, which represents the lowest level of detail at which the data is stored. The granularity should be based on your organization’s specific reporting and analytical requirements.
Conformed Dimensions: Conformed dimensions are dimensions that are shared across multiple fact tables, ensuring consistency and enabling cross-functional analysis. Design your snowflake schema with conformed dimensions to facilitate data integration and enable more comprehensive reporting and analysis.
Advantages of Snowflake Schema in Data Warehouse Modeling
The snowflake schema offers several advantages in the context of data warehouse modeling and business intelligence, including:
Data Integrity: By normalizing dimension tables, the snowflake schema can help maintain data integrity and consistency throughout the data warehouse, ensuring accurate and reliable reporting and analysis.
Reduced Data Redundancy: Normalization in the snowflake schema reduces data redundancy, which can lead to more efficient data storage and a streamlined data structure.
Scalability: The snowflake schema can easily accommodate growth in data volume and complexity, making it a scalable solution for organizations with evolving data warehousing and business intelligence needs.
Flexible Data Analysis: Although the snowflake schema has a more complex structure than the star schema, it still enables flexible data analysis, allowing users to filter, group, and aggregate data in various ways to support data-driven decision-making. This flexibility empowers users to explore and analyze data according to their specific needs and requirements.
Easier Maintenance: The snowflake schema’s focus on data integrity can make it easier to maintain and update the data warehouse over time. As a result, organizations can ensure that their data remains consistent and accurate across various analytical applications.
Balance between Performance and Integrity: The snowflake schema offers a balance between query performance and data integrity, providing a more nuanced solution for organizations with diverse reporting and analytical needs.
Implementing Snowflake Schema in Data Warehouse Modeling: Best Practices
When implementing a snowflake schema in a data warehouse, consider the following best practices:
Define Business Requirements: Begin by identifying the specific business requirements and objectives of your data warehouse and BI applications. This will help guide the design of your snowflake schema and ensure that it meets the needs of your organization.
Identify Relevant Facts and Dimensions: Determine the key facts and dimensions that are most relevant to your business requirements and will support the desired analytical capabilities.
Design Fact and Dimension Tables: Design your fact table with the appropriate granularity and use surrogate keys for the primary keys in your dimension tables. Ensure that your fact table contains foreign keys that reference the primary keys of the dimension tables, creating the snowflake shape.
Normalize Dimension Tables: Design your dimension tables with normalization in mind to eliminate redundancy and improve data integrity. This may result in a more complex structure, but it can help maintain consistent and accurate data throughout the data warehouse.
Incorporate Conformed Dimensions: Design your snowflake schema with conformed dimensions to facilitate data integration and enable more comprehensive reporting and analysis across multiple fact tables.
Test and Validate the Schema: Thoroughly test and validate your snowflake schema to ensure that it meets the business requirements and supports the desired analytical capabilities.
Monitor and Update the Schema: Regularly monitor the performance of your data warehouse and BI applications, and update the snowflake schema as needed to accommodate changes in business requirements or data volume.
Summary
The snowflake schema is a powerful data warehouse modeling technique that offers a balance between query performance and data integrity. By organizing data into a central fact table and normalized dimension tables, the snowflake schema enables flexible data analysis, reduced data redundancy, and easier maintenance, ultimately supporting data-driven decision-making in various industries and applications. By understanding the core concepts, design principles, and best practices of the snowflake schema, organizations can successfully implement this approach and leverage its many benefits to drive better business outcomes.