


Introduction: Boosting Your Predictive Power with Advanced Ensemble Techniques
Boosting methods are a class of powerful machine learning techniques designed to enhance the performance of weak or base learners. By combining multiple models iteratively and leveraging their strengths, boosting algorithms can achieve greater accuracy and predictive power than individual models. In this comprehensive guide, we will delve into the fundamentals of boosting, explore popular boosting algorithms, and provide a step-by-step guide for implementing these methods in your machine learning projects.
Understanding Boosting and its Significance in Machine Learning
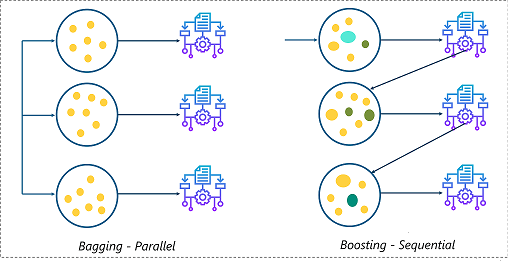
Boosting is an ensemble learning technique that aims to improve the performance of weak learners by combining their predictions in a weighted manner. In contrast to other ensemble methods like bagging, boosting focuses on reducing bias and building strong models from an iterative process. The core idea behind boosting is to sequentially train a series of models while adjusting their weights to minimize the overall error. This process effectively “boosts” the performance of weak learners, enabling them to make more accurate predictions.
The significance of boosting in machine learning lies in its ability to:
1. Improve accuracy: Boosting algorithms can significantly improve the accuracy of weak learners by combining their predictions and reducing bias.
2. Reduce overfitting: By leveraging multiple models and focusing on misclassified instances, boosting can effectively reduce overfitting and improve generalization.
3. Handle noisy data: Boosting techniques are robust to noise in the data, making them suitable for handling datasets with outliers or missing values.
4. Enhance interpretability: Boosting algorithms like decision tree-based methods can provide insights into feature importance and relationships, enhancing the interpretability of the final model.
Popular Boosting Algorithms
1. AdaBoost (Adaptive Boosting): AdaBoost is one of the earliest and most popular boosting algorithms. It combines a series of weak learners, typically decision trees, and adjusts their weights based on their performance. AdaBoost focuses on instances that are difficult to classify, iteratively reweighting the training data to prioritize misclassified instances.
2. Gradient Boosting Machine (GBM): GBM is a powerful boosting algorithm that builds an ensemble of decision trees in a sequential manner. Unlike AdaBoost, which adjusts the weights of the learners, GBM optimizes a loss function by fitting each new tree to the negative gradient of the loss function. This results in a more flexible and efficient optimization process.
3. XGBoost (eXtreme Gradient Boosting): XGBoost is an advanced implementation of the GBM algorithm designed to be more efficient, scalable, and accurate. It incorporates features such as regularization, parallelization, and early stopping to enhance the performance and speed of the boosting process.
4. LightGBM: LightGBM is a gradient boosting framework developed by Microsoft that focuses on efficiency and scalability. It uses a novel technique called Gradient-based One-Side Sampling (GOSS) to reduce the size of the data while maintaining the accuracy of the model. LightGBM also employs a technique called Exclusive Feature Bundling (EFB) to reduce the dimensionality of the data, further enhancing its efficiency.
5. CatBoost: CatBoost is a boosting algorithm developed by Yandex that is specifically designed to handle categorical features effectively. It employs a technique called Ordered Target Statistics to reduce target leakage, improving the accuracy and robustness of the model.
Implementing Boosting Methods: A Step-by-Step Guide
1. Data preprocessing: Begin by cleaning, preprocessing, and transforming your data to ensure that it is suitable for the boosting algorithm you have chosen. This may include handling missing values, encoding categorical variables, and normalizing or scaling features.
2. Select a boosting algorithm: Choose a boosting algorithm that best suits your problem, dataset, and computational resources. Consider factors such as the complexity of the data, the presence of categorical features, and the desired level of interpretability when making your decision.
3. Split the data: Divide your dataset into training and testing (or validation) sets to enable model evaluation and prevent overfitting. Typically, a 70–30 or 80–20 split is used for this purpose.
4. Train the model: Train your chosen boosting algorithm on the training data, adjusting hyperparameters as needed to optimize its performance. Some important hyperparameters to consider include the number of base learners, learning rate, maximum depth, and regularization parameters.
5. Evaluate the model: Assess the performance of your boosting model on the testing (or validation) set using appropriate evaluation metrics, such as accuracy, precision, recall, F1-score, or Mean Absolute Error (MAE), depending on your problem type. If the model’s performance is unsatisfactory, you may need to revisit your data preprocessing steps or adjust the hyperparameters to improve the model’s performance.
6. Feature importance: If desired, analyze the feature importance values provided by the boosting algorithm to gain insights into the relationships between features and the target variable. This can help you understand the underlying structure of the data and inform further feature engineering or selection efforts.
7. Model deployment: Once you are satisfied with your boosting model’s performance, deploy it to a production environment for real-time predictions or use it to inform decision-making processes within your organization.
Best Practices and Tips for Implementing Boosting Methods
1. Start with simpler models: Before diving into complex boosting algorithms, consider building simpler models such as logistic regression or decision trees to establish a baseline for comparison.
2. Cross-validation: Use cross-validation techniques, such as k-fold cross-validation, to ensure that your model’s performance is consistent across different subsets of the data.
3. Regularization: Incorporate regularization techniques, such as L1 or L2 regularization, to prevent overfitting and enhance the generalization capabilities of your boosting model.
4. Hyperparameter tuning: Perform a systematic search for optimal hyperparameters, such as grid search or random search, to fine-tune your boosting algorithm’s performance.
5. Early stopping: Implement early stopping techniques to terminate the training process when the model’s performance on the validation set begins to degrade, preventing overfitting and saving computational resources.
6. Ensemble diversity: When combining multiple boosting models, consider using models with different architectures, algorithms, or hyperparameters to increase the diversity of the ensemble and improve its overall performance.
Conclusion
Boosting methods are powerful machine learning techniques that can significantly enhance the performance of weak learners by combining their predictions in a weighted manner. With popular algorithms such as AdaBoost, GBM, XGBoost, LightGBM, and CatBoost, boosting has become a go-to technique for tackling complex prediction problems across a wide range of domains. By understanding the fundamentals of boosting, exploring various boosting algorithms, and implementing these methods in a structured and efficient manner, you can elevate your machine learning models’ performance and unlock new levels of predictive power.
Find more … …
How to tune depth parameter in boosting ensemble Classifier in Python
Boosting Ensemble Machine Learning algorithms in Python using scikit-learn
Gradient Boosting Ensembles for Classification | Jupyter Notebook | Python Data Science for beginner