P Value is a probability score that is used in statistical tests to establish the statistical significance of an observed effect. Though p-values are commonly used, the definition and meaning is often not very clear even to experienced Statisticians and Data Scientists. In this post I will attempt to explain the intuition behind p-value as clear as possible.
Introduction
In Data Science interviews, one of the frequently asked questions is ‘What is P-Value?”.
Believe it or not, even experienced Data Scientists often fail to answer this question. This is partly because of the way statistics is taught and the definitions available in textbooks and online sources.
According to American Statistical Association,
“a p-value is the probability under a specified statistical model that a statistical summary of the data (e.g., the sample mean difference between two compared groups) would be equal to or more extreme than its observed value.”
That’s hard to grasp, yes?
Alright, lets understand what really is p value in small meaningful pieces so ultimately it all makes sense.
When and how is p-value used?
To understand p-value, you need to understand some background and context behind it. So, let’s start with the basics.
When and how is p-value used?
p-values are often reported whenever you perform astatistical significance test(like t-test, chi-square test etc). These tests typically return a computed test statistic and the associated p-value. This reported value is used to establish the statistical significance of the relationships being tested.
So, whenever you see a p-value, there is an associated statistical test.
That means, there is a Hypothesis testing being conducted with a defined Null Hypothesis (H0) and a corresponding Alternate hypothesis (HA).
The p-value reported is used to make a decision on whether the null hypothesis being tested can be rejected or not.
Let’s understand a little bit more about the null and alternate hypothesis.
Now, how to frame a Null hypothesis in general?
While the null hypothesis itself changes with every statistical test, there is a general principle to frame it:
The null hypothesis assumes there is ‘no effect’ or ‘relationship’ by default.
For example: if you are testing if a drug treatment is effective or not, then the null hypothesis will assume there is not difference in outcome between the treated and untreated groups. Likewise, if you are testing if one variable influences another (say, car weight influences the mileage), then null hypothesis will postulate there is no relationship between the two.
It simply implies the absence of an effect.
Examples of Statistical Tests reporting out p-value
Here are some examples ofNull hypothesis (H0)for popular statistical tests:
- Welch Two Sample t-Test:The true difference in means of two samples is equal to 0
- Linear Regression:The beta coefficient(slope) of the X variable is zero
- Chi Square test:There is no difference between expected frequencies and observed frequencies.
Get the feel?
But how would the alternate hypothesis would look like?
Thealternate hypothesis (HA)is always framed to negate the null hypothesis. The corresponding HA for above tests are as follows:
- Welch Two Sample t-Test:The true difference in means of two samples is NOT equal to 0
- Linear Regression:The beta coefficient(slope) of the X variable is NOT zero
- Chi Square test:The difference between expected frequencies and observed frequencies is NOT zero.
What p-value really is
Now, back to the discussion on p-value.
Along with every statistical test, you will get a corresponding p-value in the results output.
What is this meant for?
It is used to determine if the data is statistically incompatible with the null hypothesis.
Not clear eh?
Let me put it in another way.
The P Value basically helps to answer the question: ‘Does the data really represent the observed effect?’.
This leads us to a more mathematical definition of P-Value.
The P Value isthe probability of seeing the effect(E) when the null hypothesis is true.
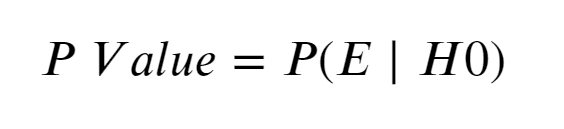
If you think about it, we want this probability to be very low.
Having said that, it is important to remember that p-value refers to not only what we observed but also observations more extreme than what was observed. That is why the formal definition of p-value contain the statement ‘would be equal to or more extreme than its observed value.’
How is p-value used to establish statistical significance
Now that you know, p value measures the probability of seeing the effect when the null hypothesis is true.
A sufficiently low value is required to reject the null hypothesis.
Notice how I have used the term ‘Reject the Null Hypothesis’ instead of stating the ‘Alternate Hypothesis is True’.
That’s because, we have tested the effect against the null hypothesis only.
So,when the p-value is low enough, we reject the null hypothesis and conclude the observed effect holds.
But how low is ‘low enough’ for rejecting the null hypothesis?
This level of ‘low enough’ cutoff is called the alpha level, and you need to decide it before conducting a statistical test.
But how low is ‘low enough’?
Practical Guidelines to set the cutoff of Statistical Significance (alpha level)
Let’s first understand what is Alpha level.
It is the cutoff probability for p-value to establish statistical significance for a given hypothesis test.
For an observed effect to be considered as statistically significant, the p-value of the test should be lower than the pre-decided alpha value.
Typically for most statistical tests(but not always), alpha is set as 0.05.
In which case, it has to be less than 0.05 to be considered as statistically significant.
What happens if it is say, 0.051?
It is still considered as not significant. We do NOT call it as a weak statistical significant.
It is either black or white. There is no gray with respect to statistical significance.
Now, how to set the alpha level?
Well, the usual practice is to set it to 0.05.
But when the occurrence of the event is rare, you may want to set a very low alpha. The rarer it is, the lower the alpha.
For example in the CERN’s Hadron collider experiment to detect Higgs-Boson particles(which was very rare), the alpha level was set so low to 5 Sigma levels, which means a p value of less than 3 * 10^-7 is required reject the null hypothesis.
Whereas for a more likely event, it can go up to 0.1.
Secondly, more the samples (number of observations) you have the lower should be the alpha level. Because, even a small effect can be made to produce a lower p-value just by increasing the number of observations.
The opposite is also true, that is, a large effect can be made to produce high p value by reducing the sample size.
In case you don’t know how likely the event can occur, its a common practice to set it as 0.05. But, as a thumb rule, never set the alpha greater than 0.1.
Having said that the alpha=0.05 is mostly an arbitrary choice. Then why do most people still use p=0.05?
That’s because thats what is taught in college courses and being traditionally used by the scientific community and publishers.
What P Value is Not
Given the uncertainty around the meaning of p-value, it is very common to misinterpret and use it incorrectly.
Some of the common misconceptions are as follows:
- P-Value is the probability of making a mistake. Wrong!
- P-Value measures the importance of a variable. Wrong!
- P-Value measures the strength of an effect. Wrong!
A smaller p-value does not signify the variable is more important or even a stronger effect.
Why?
Because, like I mentioned earlier, any effect no matter how small can be made to produce smaller p-value only by increasing the number of observations (sample size).
Likewise, a larger value does not imply a variable is not important.
For a sound communication, it is necessary to report not just the p-value but also the sample size along with it. This is especially necessary if the experiments involve different sample sizes.
Secondly, making inferences and business decisions should not be based only on the p-value being lower than the alpha level.
Analysts should understand the business sense, understand the larger picture and bring out the reasoning before making an inference and not just rely on the p-value to make the inference for you.
Does this mean the p-value is not useful anymore?
Not really. It is a useful tool because it provides an objective standard for everyone to assess. Its just that you need to use it the right way.
Example: How to find p-value for linear regression
Linear regressionis a traditional statistical modeling algorithm that is used to predict a continuous variable (a.k.a dependent variable) using one or more explanatory variables.
Let’s see an example of extracting the p-value with linear regression using themtcarsdataset. In this dataset the specifications of the vehicle and the mileage performance is recorded.
We want to use linear regression to test if one of the specs “the ‘weight’ (wt) of the vehicle” has a significant relationship (linear) with the ‘mileage’ (mpg).
This can be conveniently done using python’sstatsmodelslibrary. But first, let’s load the data.
Withstatsmodelslibrary
/* Load Packagesimport pandas as pd */
import statsmodels.formula.api as smf
/* Import data */
df = pd.read_csv('mtcars.csv', usecols=['mpg','wt'])
df.head()| mpg | wt | |
|---|---|---|
| 0 | 4.582576 | 2.620 |
| 1 | 4.582576 | 2.875 |
| 2 | 4.774935 | 2.320 |
| 3 | 4.626013 | 3.215 |
| 4 | 4.324350 | 3.440 |
The X(wt) and Y (mpg) variables are ready.
Null Hypothesis (H0): The slope of the line of best fit (a.k.a beta coefficient) is zero
Alternate Hypothesis (H1): The beta coefficient is not zero.
To implement the test, use thesmf.ols()function available in theformula.apiofstatsmodels. You can pass in the formula itself as the first argument and callfit()to train the linear model.
/* Train model */
model = smf.ols('mpg ~ wt', data=df).fit()Once model is trained, callmodel.summary()to get a comprehensive view of the statistics.
/* Resultsprint(model.summary()) */The p-value is located in under theP>|t|againstwtrow. If you want to extract that value into a variable, usemodel.pvalues.
/* P-Valuesprint(model.pvalues) */Intercept4.891527e-25
wt 2.146343e-11
dtype: float64Since the p-value is much lower than the significance level (0.01), we reject the null hypothesis that the slope is zero and take that the data really represents the effect.
Well, that was just one example of computing p-value.
Whereas p-value can be associated with numerous statistical tests. If you are interested in finding out more about how it is used, see moreexamples of statistical testswith p-values.
Conclusion
In this post we covered what exactly is a p-value and how and how not to use it. We also saw a python example related to computing the p-value associated with linear regression.
Now with this understanding, let’s conclude what is the difference between Statistical Model from Machine Learning model?
Well, while both statistical as well as machine learning models are associated with making predictions, there can be many differences between these two. But most simply put, any predictive model that has p-values associated with it are considered as statistical model.
Python Example for Beginners

Two Machine Learning Fields
There are two sides to machine learning:
- Practical Machine Learning:This is about querying databases, cleaning data, writing scripts to transform data and gluing algorithm and libraries together and writing custom code to squeeze reliable answers from data to satisfy difficult and ill defined questions. It’s the mess of reality.
- Theoretical Machine Learning: This is about math and abstraction and idealized scenarios and limits and beauty and informing what is possible. It is a whole lot neater and cleaner and removed from the mess of reality.
Data Science Resources: Data Science Recipes and Applied Machine Learning Recipes
Introduction to Applied Machine Learning & Data Science for Beginners, Business Analysts, Students, Researchers and Freelancers with Python & R Codes @ Western Australian Center for Applied Machine Learning & Data Science (WACAMLDS) !!!
Latest end-to-end Learn by Coding Recipes in Project-Based Learning:
Applied Statistics with R for Beginners and Business Professionals
Data Science and Machine Learning Projects in Python: Tabular Data Analytics
Data Science and Machine Learning Projects in R: Tabular Data Analytics
Python Machine Learning & Data Science Recipes: Learn by Coding
R Machine Learning & Data Science Recipes: Learn by Coding
Comparing Different Machine Learning Algorithms in Python for Classification (FREE)
Disclaimer: The information and code presented within this recipe/tutorial is only for educational and coaching purposes for beginners and developers. Anyone can practice and apply the recipe/tutorial presented here, but the reader is taking full responsibility for his/her actions. The author (content curator) of this recipe (code / program) has made every effort to ensure the accuracy of the information was correct at time of publication. The author (content curator) does not assume and hereby disclaims any liability to any party for any loss, damage, or disruption caused by errors or omissions, whether such errors or omissions result from accident, negligence, or any other cause. The information presented here could also be found in public knowledge domains.