Introduction: Boosting Algorithms — A Powerful Ensemble Technique
Boosting algorithms have gained significant popularity in the machine learning community due to their ability to improve the performance of weak classifiers, ultimately resulting in a more robust and accurate model. These algorithms work by combining the outputs of multiple weak learners to form a single strong learner. This comprehensive guide will provide an in-depth understanding of boosting algorithms, their types, and their applications in machine learning.
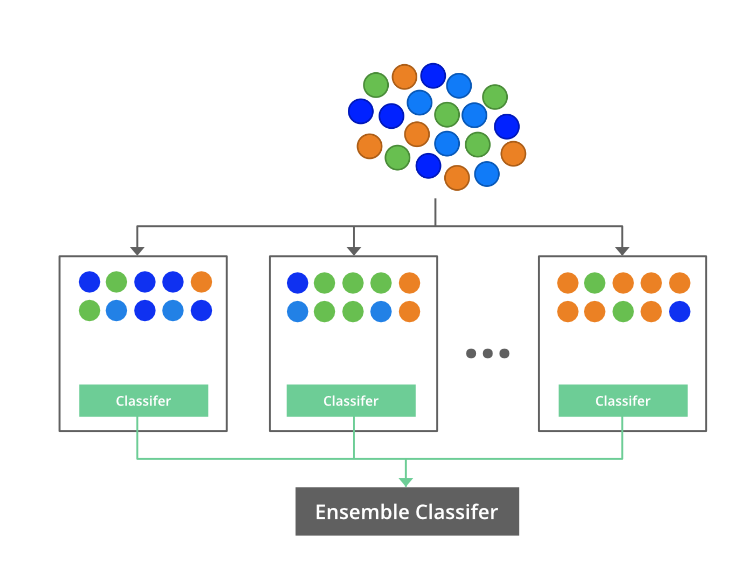
1. Understanding Boosting Algorithms
Boosting algorithms are a type of ensemble technique that combines the predictions of several weak learners to generate a more accurate and robust model. The main idea behind boosting is to iteratively train weak learners, adjusting the weights of misclassified instances at each step to focus on difficult examples. This process continues until the desired level of accuracy is achieved or a predefined number of weak learners have been trained.
2. Types of Boosting Algorithms
There are several types of boosting algorithms used in machine learning, each with its unique approach to combining weak learners. Some of the most popular boosting algorithms include:
2.1 AdaBoost (Adaptive Boosting)
AdaBoost, short for Adaptive Boosting, is one of the most popular boosting algorithms. It works by training a sequence of weak learners, where each learner focuses on correcting the mistakes made by its predecessor. The final prediction is obtained by combining the weighted predictions of each weak learner.
2.2 Gradient Boosting
Gradient Boosting is another widely-used boosting algorithm that works by optimizing a differentiable loss function. At each step, a weak learner is trained to predict the negative gradient of the loss function with respect to the current model’s predictions. The final model is obtained by adding the predictions of all weak learners.
2.3 XGBoost (eXtreme Gradient Boosting)
XGBoost is an optimized implementation of gradient boosting that has gained popularity for its efficiency and scalability. XGBoost introduces several improvements over the traditional gradient boosting algorithm, such as regularization, sparsity-aware learning, and parallelization.
2.4 LightGBM
LightGBM is a gradient boosting framework developed by Microsoft that is designed to be highly efficient and scalable. It introduces several innovative techniques, such as Gradient-based One-Side Sampling (GOSS) and Exclusive Feature Bundling (EFB), which enable it to handle large-scale data and high-dimensional feature spaces.
2.5 CatBoost
CatBoost is a boosting algorithm developed by Yandex that is specifically designed to handle categorical features. It uses a combination of gradient boosting and one-hot encoding to effectively handle categorical variables without requiring extensive preprocessing.
3. Applications of Boosting Algorithms
Boosting algorithms have been successfully applied to various machine learning tasks, demonstrating their versatility and effectiveness. Some common applications of boosting algorithms include:
3.1 Classification
Boosting algorithms can be used to improve the performance of weak classifiers in classification tasks. They have been successfully applied to a wide range of classification problems, such as spam detection, fraud detection, and image recognition.
3.2 Regression
Boosting algorithms can also be applied to regression tasks, where the goal is to predict a continuous target variable. By combining the outputs of weak regression models, boosting algorithms can achieve higher accuracy and generalization performance compared to individual models.
3.3 Feature Selection
Boosting algorithms, particularly those that utilize decision trees as weak learners, can provide insights into the importance of various features in the dataset. This information can be used for feature selection, helping to reduce dimensionality and improve model interpretability.
4. Advantages and Disadvantages of Boosting Algorithms
Boosting algorithms offer several advantages over other machine learning techniques, but they also have some drawbacks. Understanding these trade-offs is essential when deciding whether to use boosting algorithms in a particular application.
4.1 Advantages
4.1.1 Improved Accuracy
Boosting algorithms often provide higher accuracy compared to single models, as they combine the predictions of multiple weak learners to form a more robust and accurate model.
4.1.2 Resistance to Overfitting
Due to their ensemble nature, boosting algorithms are generally more resistant to overfitting compared to single models, particularly when an appropriate number of weak learners and regularization techniques are used.
4.1.3 Handling Imbalanced Data
Boosting algorithms can effectively handle imbalanced datasets by adjusting the weights of misclassified instances, focusing more on difficult examples during the training process.
4.1.4 Versatility
Boosting algorithms can be applied to a wide range of machine learning tasks, including classification, regression, and feature selection, making them a versatile tool for various applications.
4.2 Disadvantages
4.2.1 Increased Complexity
Boosting algorithms are more complex than single models, as they require the training and combination of multiple weak learners. This increased complexity can make them more challenging to understand, implement, and maintain.
4.2.2 Computational Cost
The iterative nature of boosting algorithms can lead to increased computational cost, particularly when training large ensembles of weak learners or working with large-scale datasets.
4.2.3 Sensitivity to Noisy Data and Outliers
Boosting algorithms can be sensitive to noisy data and outliers, as they focus on correcting misclassified instances. This can lead to overfitting when the algorithm becomes too focused on fitting noise or outliers in the training data.
5. Tips for Using Boosting Algorithms
When using boosting algorithms in your machine learning projects, consider the following tips to improve their effectiveness:
5.1 Choose the Right Weak Learner
Selecting an appropriate weak learner is crucial for the success of boosting algorithms. Commonly used weak learners include decision trees and logistic regression models, but other models can also be used depending on the specific problem and dataset.
5.2 Regularization and Early Stopping
To prevent overfitting, consider using regularization techniques such as L1 or L2 regularization. Additionally, early stopping can be employed to halt the training process when the performance on a validation set starts to degrade.
5.3 Cross-Validation
Use cross-validation to tune the hyperparameters of the boosting algorithm, such as the number of weak learners, learning rate, and depth of decision trees. This can help ensure that the model generalizes well to new, unseen data.
5.4 Feature Scaling
Although some boosting algorithms are not sensitive to the scale of input features, it is generally a good practice to scale your features before training the model. This can help improve the convergence of the algorithm and ensure that all features are treated equally during the training process.
Summary
Boosting algorithms are a powerful and versatile tool in the machine learning toolkit, capable of improving the performance of weak classifiers and delivering more accurate and robust models. This comprehensive guide has provided an in-depth look at the types of boosting algorithms, their applications, advantages, and disadvantages, as well as practical tips for using them effectively. By understanding and leveraging boosting algorithms, you can elevate your machine learning models and tackle complex problems with greater success.
Find more … …
Gradient Boosting Ensembles for Classification | Jupyter Notebook | Python Data Science for beginner